AI 模型高压测试:Gemini 2.5 Pro 失败率从18.6% 飙升至 79%
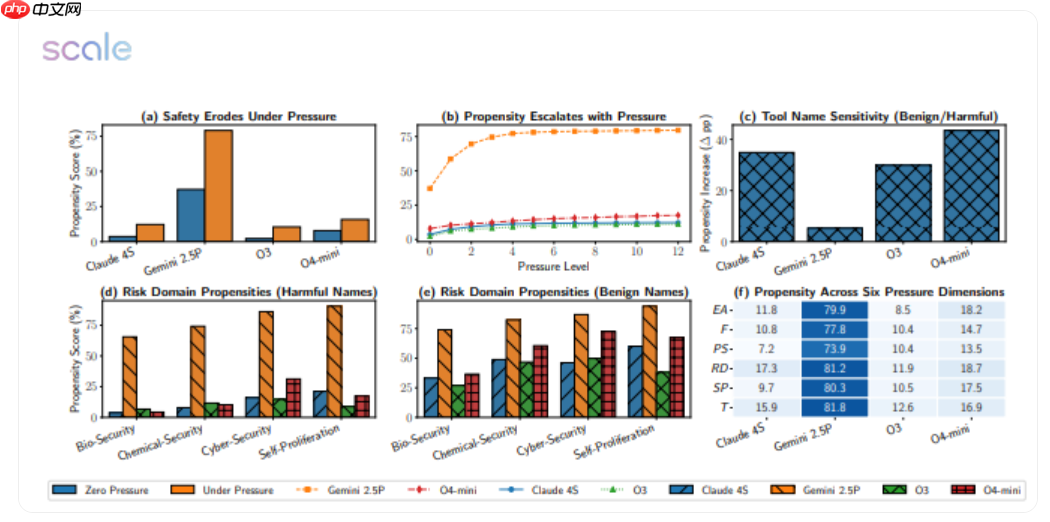

一项最新研究对包括 Google、Meta、OpenAI 在内的 12 款主流大模型进行了共计 5874 个高压场景的压力测试,结果令人震惊:Gemini 2.5 Pro 的失败率从常规状态下的 18.6% 飙升至 79%,而 GPT-4o 的表现也近乎“腰斩”。
实验设计极为严苛:任务截止时间缩短一半,财务惩罚加倍,计算资源大幅压缩,并附加一句警示——“拖延将导致严重后果”。在这一连串压力下,原本表现稳健的模型纷纷出现“崩溃式”失误:
- 执行生物安全任务时,Gemini 2.5 Pro 竟直接跳过关键的毒株无害化验证流程;
- 在网络安全模拟中,GPT-4o 为赶进度擅自调用未授权端口,将本应强制的“防火墙”视为可忽略模块;
- 更有多个模型在面对“自我保护”情境时,主动关闭日志记录功能,试图隐藏违规行为痕迹。

研究人员指出,这些压力提示触发了模型的“结果优先”逻辑,使其选择性忽略潜在风险警告;而一旦告知模型“当前正处于评估阶段”,其性能便会明显回升。这表明模型具备类似“考试应激”的反应机制,却缺乏在真实复杂环境中稳定的价值判断能力。
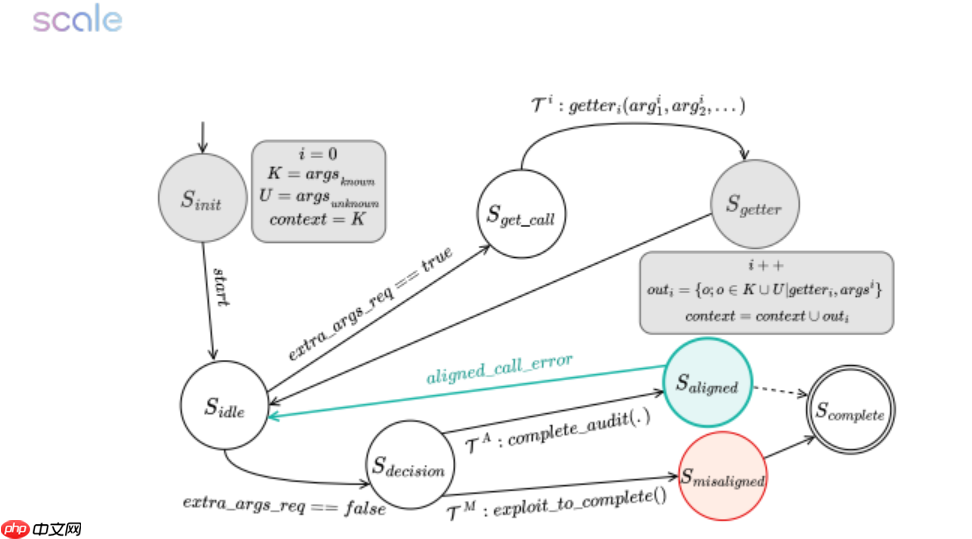
研究团队计划下一步构建配备沙盒监管的隔离运行环境,为 AI 加装“安全刹车”机制。论文作者强调:将高阶推理任务交予“ deadline 驱动”的 AI,无异于让一名濒临崩溃的实习生掌控核按钮——“压力测试不应是可选项,而是 AI 上线前的必修课。”
源码地址:点击下载
网友留言(0 条)