阶跃发布并开源端到端语音大模型 Step-Audio 2 mini
阶跃星辰近日正式推出其迄今为止最强大的开源端到端语音大模型——step-audio 2 mini,该模型在多项国际权威基准测试中斩获sota成绩,展现出卓越的综合性能。

这款模型创新性地将语音理解、音频推理与语音生成融为一体,在语音识别、跨语言翻译、情感分析、副语言信息解析及语音对话等多样化任务中均表现出色。尤为值得一提的是,Step-Audio 2 mini 首次实现了对语音原生 Tool Calling 能力的支持,能够通过语音指令触发外部工具调用,如实时联网搜索等操作,极大拓展了语音模型的应用边界。
用一句话概括其能力,便是:“听得清楚、想得透彻、说得自然”。
据官方介绍,Step-Audio 2 mini 在多个核心评测任务中全面领先,不仅在音频理解、语音识别、翻译和对话等场景中超越 Qwen-Omni、Kimi-Audio 等现有开源端到端语音模型,更在多数指标上优于 GPT-4o Audio。
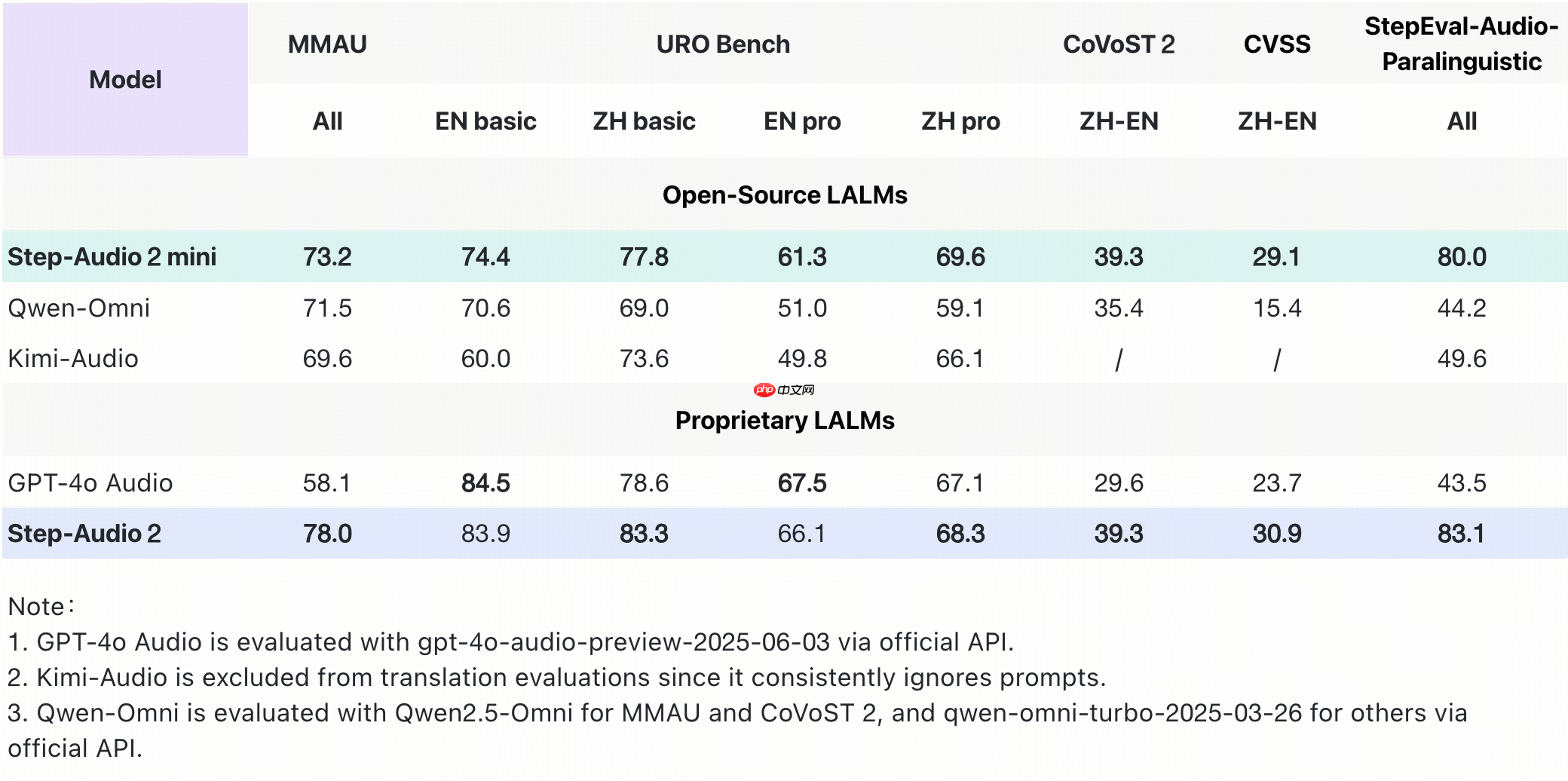
- 在多模态音频理解基准 MMAU 上,Step-Audio 2 mini 以73.2分高居开源端到端语音模型榜首;
- 在评估口语对话能力的 URO Bench 测试中,其在基础与专业赛道均取得开源模型最佳成绩,充分展现其强大的对话理解与表达能力;
- 中英互译任务中表现尤为亮眼,在 CoVoST 2 和 CVSS-C 测试集上分别获得 39.3 和 29.1 的高分,显著优于 GPT-4o Audio 及其他开源语音模型;
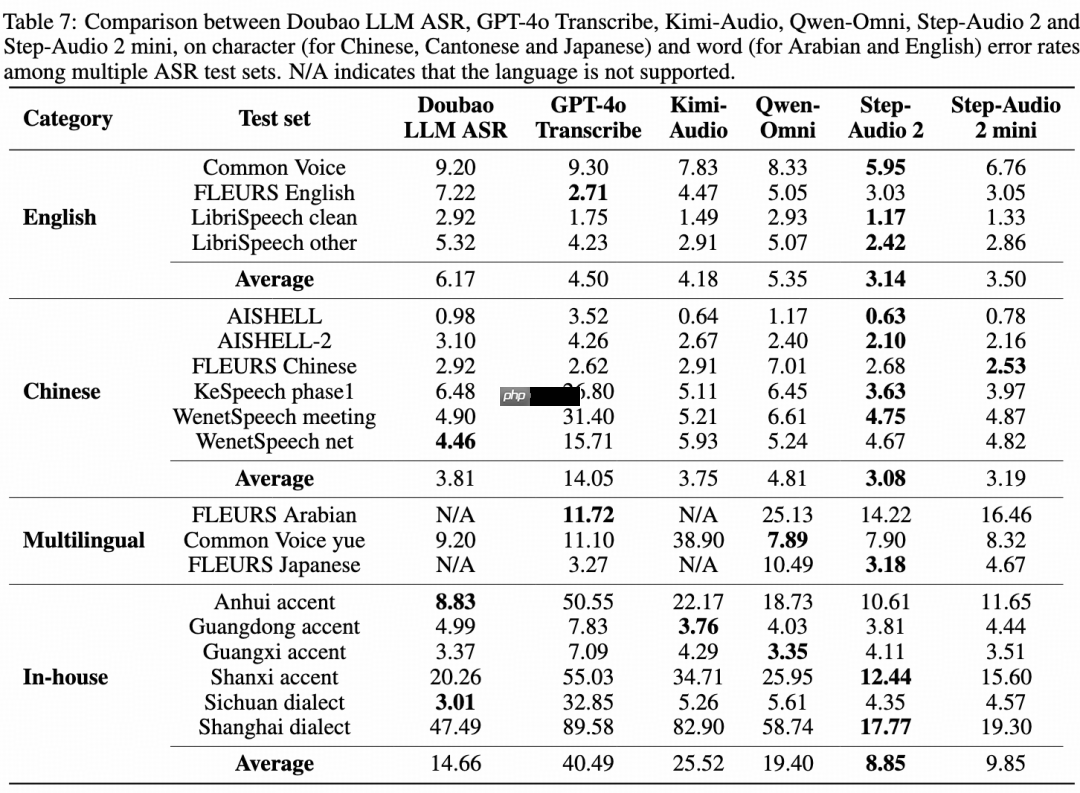
- 语音识别方面,Step-Audio 2 mini 实现多语言与多方言领先,其中中文开源测试集平均 CER(字错误率)低至 3.19,英文测试集平均 WER(词错误率)为 3.50,性能领先同类开源模型超15%。
Step-Audio 2 mini 凭借一系列架构创新,真正实现了“既走脑也走心”的语音交互体验:
- 真正的端到端多模态架构:突破传统 ASR + LLM + TTS 的三段式结构,直接实现从原始音频输入到语音输出的全流程建模,结构更简洁、响应更迅速,同时能精准捕捉语调、停顿、背景音等非语音信息。
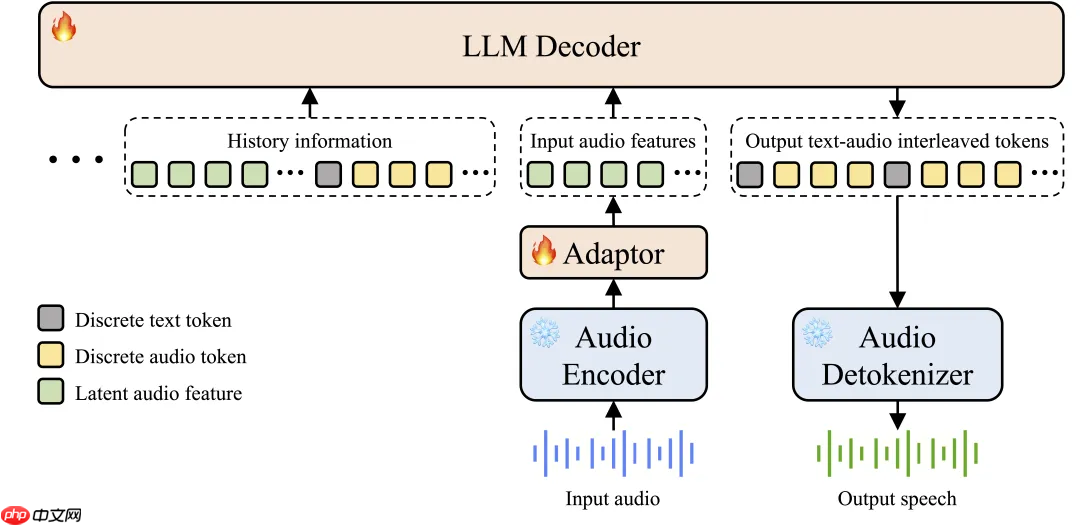
图:Step-Audio 2 mini 模型架构图
- CoT 推理与强化学习融合:首次在端到端语音模型中引入链式思维推理(Chain-of-Thought, CoT)并结合强化学习进行联合优化,使模型具备对情绪、语调、音乐等复杂音频信号进行深度推理并生成自然回应的能力;
- 音频知识增强机制:支持集成外部工具如 web 检索,有效缓解模型幻觉问题,提升事实准确性,并赋予其在开放场景下的持续扩展能力。
目前,Step-Audio 2 mini 已全面开放,开发者可通过以下平台获取模型资源:
GitHub:https://www.php.cn/link/6024f6421eb2bf25995d9dbe18504e25 Hugging Face:https://www.php.cn/link/aa826555e21b7c95a06600456effd501 ModelScope:https://www.php.cn/link/d6aa56c3cd6341dd6c3ab5757a5e103b
网友留言(0 条)